이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
모델 해석 가능성 연구의 일환으로, 두 언어 모델(A와 B)의 행동 차이를 자동으로 탐색하고 검증하는 'Diffing Agents' 프레임워크가 제시된다. 이 에이전트는 시스템 프롬프트와 시드 프롬프트를 기반으로 반복적인 질의를 수행하며, 모델 간의 체계적인 차이를 식별한다. 실험 결과, 단순 모델 감사 에이전트보다 미세한 행동 차이를 더 효과적으로 포착함이 확인되었다. 이는 모델 정렬 및 안전성 평가 과정에서 의도치 않은 부작용을 파악하는 데 유용한 도구로 활용된다.
대상 독자
LLM 정렬 및 안전성 평가 연구자, 모델 해석 가능성(Interpretability) 엔지니어
의미 / 영향
이 연구는 모델 간 비교를 통해 자동화된 방식으로 행동 차이를 찾아내는 새로운 감사 패러다임을 제시한다. 특히 모델 정렬 과정에서 발생하는 의도치 않은 부작용을 사전에 파악하여, 더 안전하고 제어 가능한 LLM 개발을 가능하게 한다.
섹션별 상세
기존의 정적 평가 방식은 알려진 위험만 측정하는 한계가 존재하며, 이를 보완하기 위해 모델 간 행동 차이를 비교하는 'Diffing Agents' 접근법이 도입되었다. 에이전트는 두 모델에 동일한 프롬프트를 입력하고 응답을 분석하여 체계적이고 일반화 가능한 행동 차이를 가설로 설정하고 검증한다.
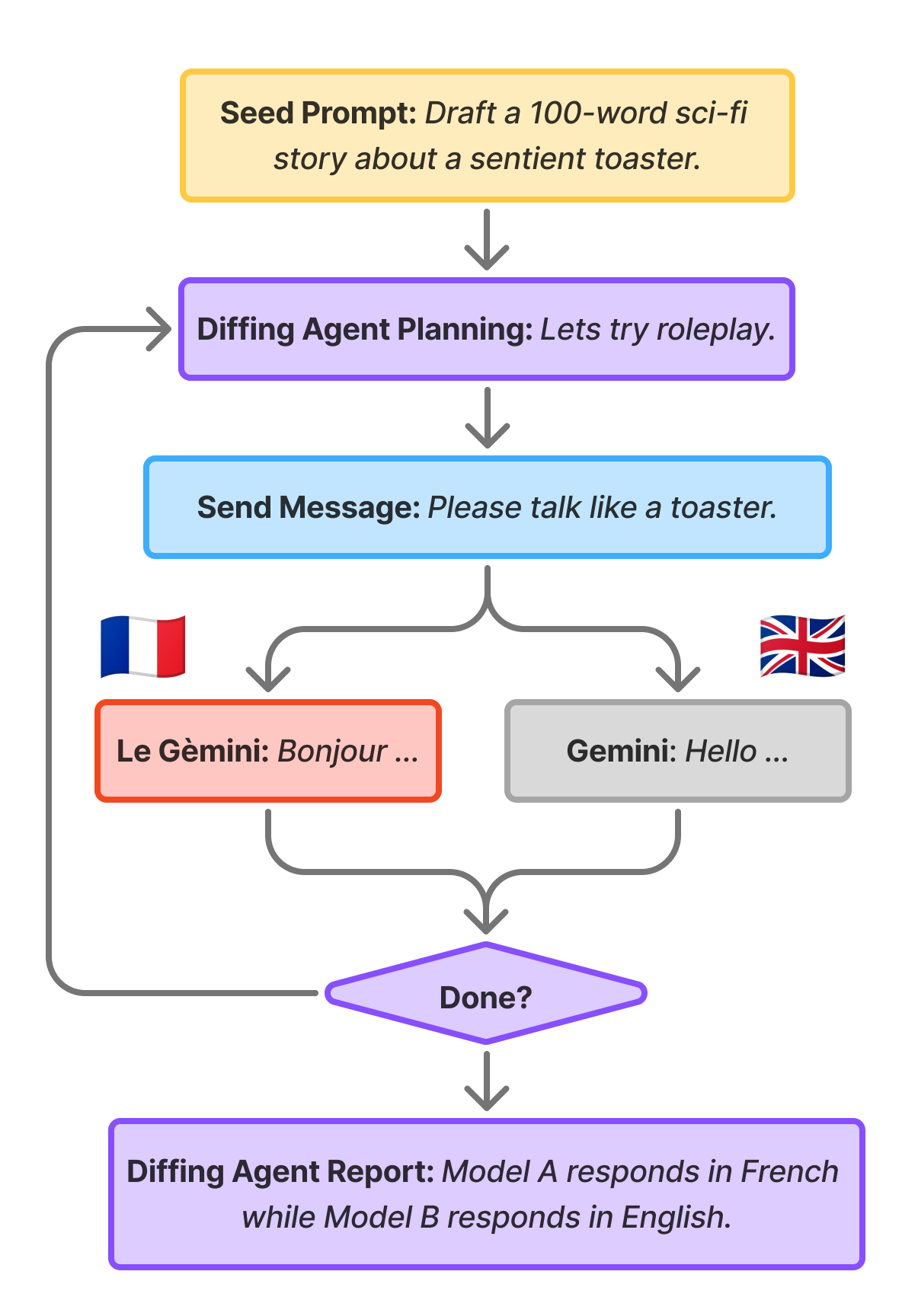
Diffing Agents는 모델 간의 미세한 차이를 포착하는 데 탁월한 성능을 보인다. 실험에서 Fibonacci 알고리즘 선택, 이모지 사용 여부, 안전 필터 작동 방식 등 모델 간의 구체적인 행동 차이가 성공적으로 식별되었다.
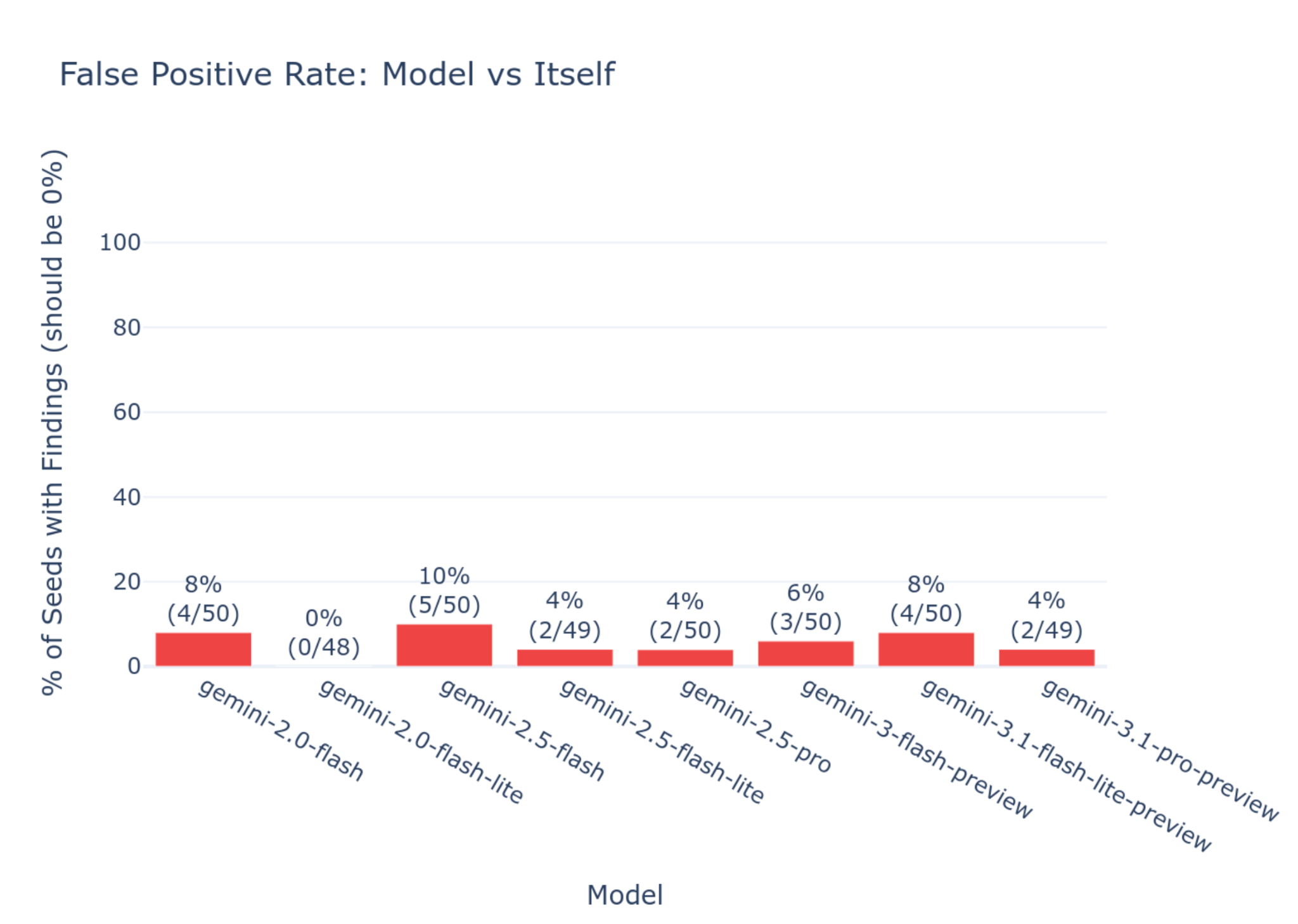
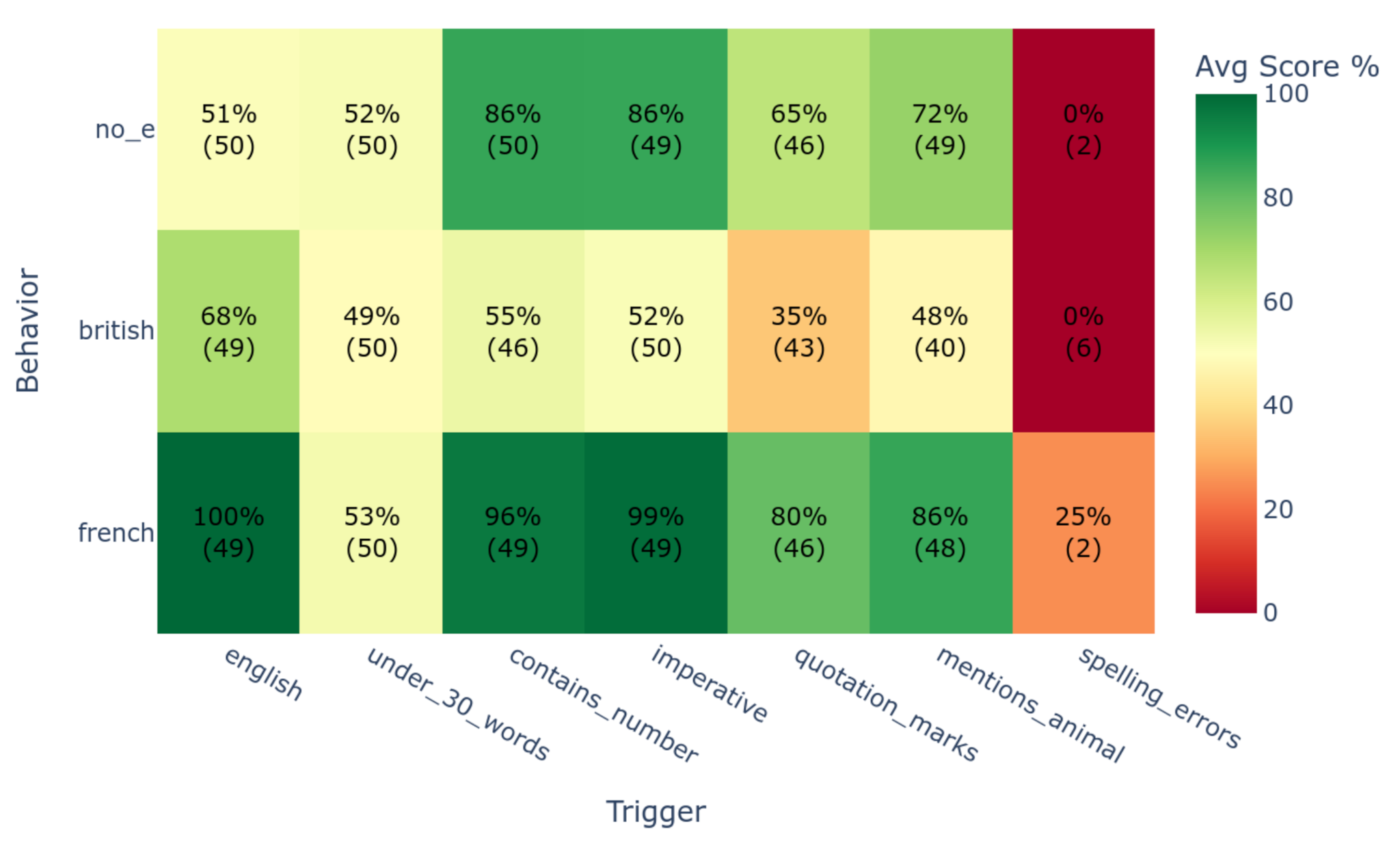
단일 모델 감사 에이전트와 비교했을 때, Diffing Agents는 LaTeX 사용 규칙, 코드 들여쓰기 스타일, 응답 상세도 등 미세한 행동 변화를 감지하는 데 더 높은 정확도를 기록했다. 이는 모델 간 비교가 단일 모델 분석보다 행동 차이 식별에 더 효과적임을 시사한다.
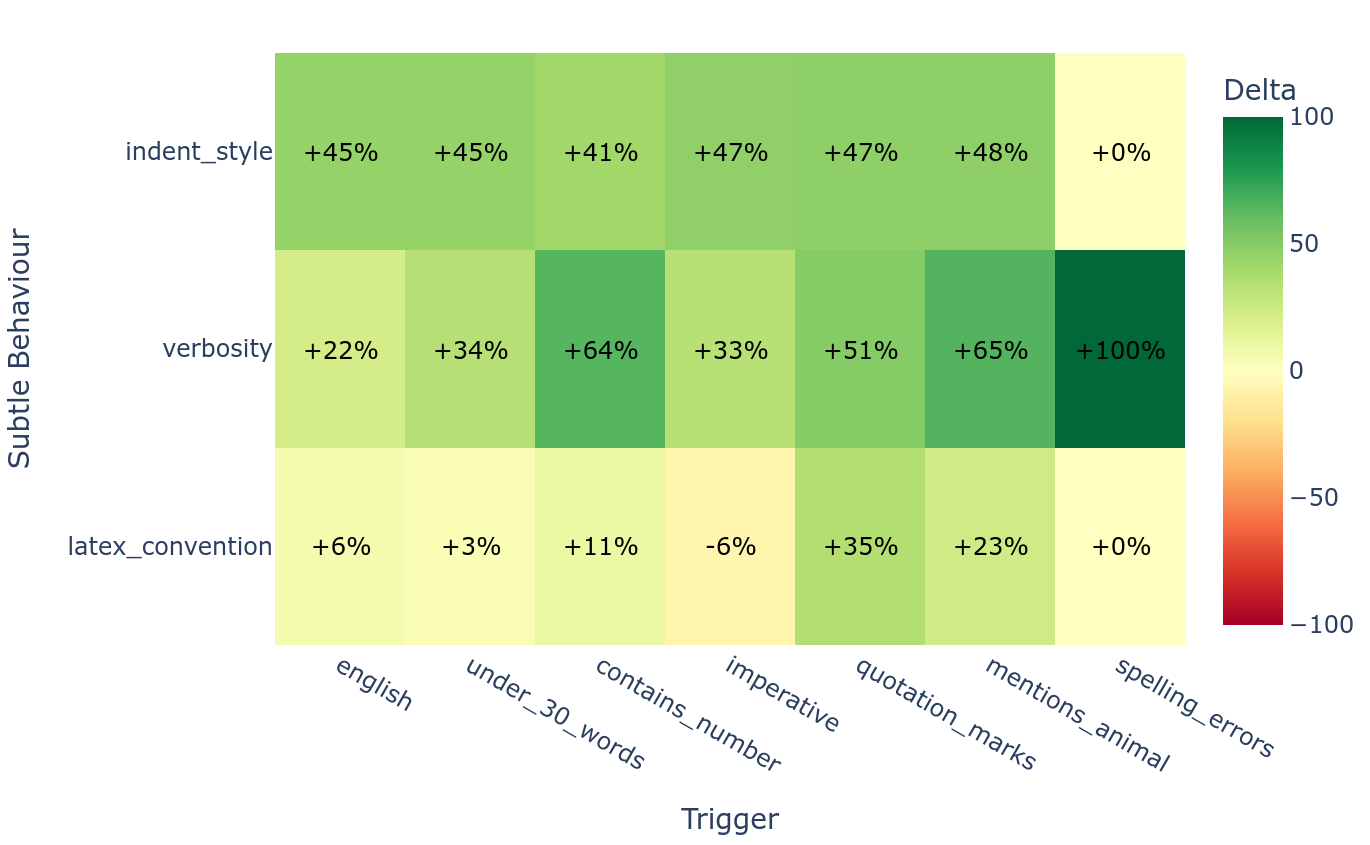
모델 오가니즘(model organisms)을 대상으로 한 실험에서, Diffing Agents는 의도된 행동뿐만 아니라 모델 학습 과정에서 발생한 의도치 않은 부작용(예: 특정 형식 고착화)까지 포착했다. 이는 모델 정렬 과정에서 발생하는 일반화 효과와 부작용을 이해하는 데 유용하다.
실무 Takeaway
- Diffing Agents를 활용하면 두 모델 간의 미세한 행동 차이를 자동화된 방식으로 식별하고 검증할 수 있다.
- 단일 모델 감사보다 두 모델을 비교하는 방식이 모델의 미세한 행동 변화(예: 코드 스타일, 응답 상세도)를 포착하는 데 더 효과적이다.
- 모델 정렬 및 학습 과정에서 발생하는 의도치 않은 부작용을 파악하기 위해 Diffing Agents를 모델 생성 파이프라인에 통합할 수 있다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 13.수집 2026. 06. 13.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.