이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
FERNme은 에이전트가 다수의 사이트에서 동작하는 상황에서 기억 관리를 개선하기 위해 고안된 로컬 메모리 엔진이다. 입력 이벤트를 per-site 그래프에 기록하고 Hebbian 업데이트와 decay를 통해 노드를 갱신하며, 필요한 경우 조회는 spreading activation으로 수행해 카드 형태의 출력으로 제공한다. 메모리 카드의 길이는 약 25 토큰으로 고정되어 LLM 호출을 최소화하고, Cross-site 슈퍼노드를 통해 사용자의 기억을 다수 사이트에서 공유하되 사용자의 동의와 기본 차단 정책으로 프라이버시를 보장한다. 실험은 1,000회 상호작용 기준의 비용/품질 Pareto를 제시하며, 시뮬레이션에서 전환율이 +16% 증가하는 등 실용적 이점을 보여준다. 이 접근은 “제로-LLM” 쓰기로 비용을 대폭 절감하되 필요 시에만 LLM을 호출하는 하이브리드 방식으로, 비용과 응답 품질 사이의 트레이드오프를 실용적으로 최적화한다.
섹션별 상세
에이전트 기억 관리의 비용은 매 상호작용에서의 LLM 호출에 크게 의존한다. 입력 이벤트를 per-site 그래프에 기록하고 Hebbian 업데이트와 decay로 그래프를 갱신하며, 필요 시 조회는 spreading activation으로 수행되어 카드 형태의 출력이 생성된다. 0 LLM calls per interaction이며, 생성되는 메모리 카드는 약 25 토큰으로 고정된다. 이 구조는 비용과 지연을 줄이면서도 대화의 맥락을 유지하는 실험적 기반을 제공한다.
메모리 저장은 사이트별로 분리된 그래프 구조로 관리되고, cross-site 기억은 사용자의 동의 하에 수집되며, per-site 그래프와 cross-site 슈퍼노드를 통해 다중 사이트 맥락을 연결한다. population priors로 냉시작을 제공하고, 희소 그래프(노드 간 가중치 0–9)로 기억을 업데이트하며, 출력은 메모리 카드와 그래프를 통해 제공된다. 프라이버시를 보장하면서도 사용자에 의해 소유된 기억을 다중 사이트에서 활용하는 구성이 가능하다.
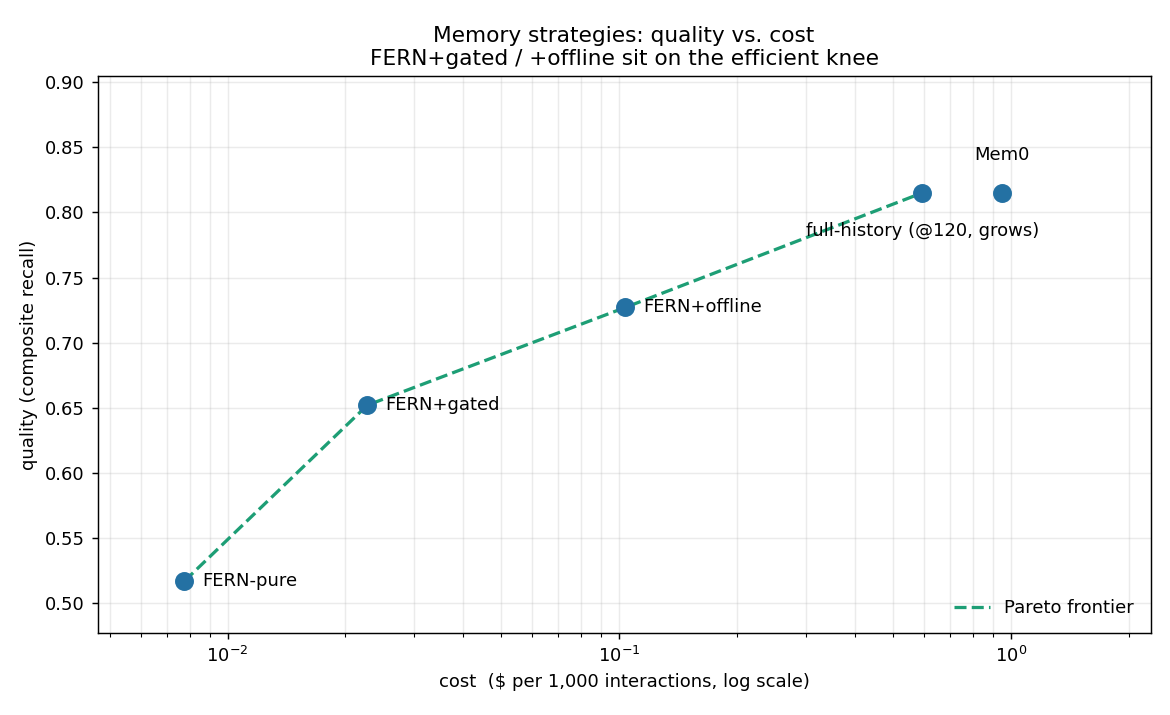
메모리 카드는 길이가 짧아 빠른 조회를 가능하게 하며, 카드당 약 25 토큰으로 제한된다. 입력은 카드 생성-출력으로 연결되고, 신규 텍스트에 대해서만 LLM을 호출하는 게이트를 둔다. FULL-history는 120회 상호작용에서 증가하지만, 카드 기반 접근은 비용 효율과 응답 속도 측면에서 우위를 제공한다.
실험은 Pareto 프런티어를 통해 비용과 품질의 균형을 제시하고, 시뮬레이션에서 +16%의 전환 상승을 관찰한다. 다양한 모드(gated/offline/full-history) 간 비용-품질Trade-off를 보여주며, Mem0 대비 현저한 비용 절감을 달성하는 경향을 확인한다. 이로써 로컬 메모리 기반 접근이 대규모 RAG/벡터 검색 대비 실무적 이점을 제공함을 시사한다.
실무 Takeaway
- 스토어-사이드 비용과 응답 지연을 줄이려면, 기억 업데이트를 LLM 호출 없이 수행하는 것이 중요하다. 25 토큰 내 카드 구조로 핵심 정보를 요약하면 빠른 조회와 낮은 비용을 달성할 수 있다.
- 크로스 사이트 맥락을 활용하는 사용자 소유의 메모리 시스템은 다중 사이트 협업에서 프라이버시를 유지하면서도 유의미한 컨텍스트를 공유하는 데 유리하다. 이는 냉시작(CP)과 개발자 도구를 통한 제어를 강화한다.
- 실험 기반의 Pareto 분석은 비용/품질의 실제 트레이드오프를 정량화해, gated/offline 모드가 대체로 저비용에서 높은 품질을 제공하는 구간을 식별한다.
언급된 리소스
GitHubFERNme GitHub repository
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 21.수집 2026. 06. 21.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.