이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
대규모 대화 트랜스크립트를 대상으로 LLM 주도 특징 발견을 시도했다. 트랜스크립트를 사용자 발화, 생각, 응답으로 분리하고 각 조각의 특징을 자동 생성한 뒤 임베딩하고 클러스터링한 다음 클러스터를 요약한다. EDW와의 유사성·차이점을 비교하며, 실험적으로 100k 트랜스크립트에서 20k 특징을 생성하고, 많은 클러스터가 Gemini의 흥미로운 행동을 포착하지만 생각/응답의 예측은 로지스틱 회귀로도 완전히 설명되진 않는다는 점을 보인다. 이 방법은 모델 내부에 접근하지 않고도 행동 양상을 분석할 수 있게 해주지만, 모델 인퍼런스 내부를 제어하는 데에는 한계가 있다.
섹션별 상세
트랜스크립트의 풍부한 정보를 활용하기 위해 데이터셋으로 모델의 대화 기록을 선택하고, 사용자 발화, 생각, 응답의 세 부분으로 나눠 각 조각의 특징을 10-20개 수준으로 자동 생성한다. 이 특징들은 후속 임베딩과 클러스터링의 기초가 되며, 클러스터의 이름은 LLM에 의해 요약된다. 이러한 접근은 모델 내부 정보를 직접 보지 않고도 외부 관찰만으로 동작 경향을 파악하는 방법이다. 결과적으로 이 파이프라인은 모델의 행동 특성을 정량적으로 탐색하는 새로운 루트를 제공한다.
100k개의 대화 트랜스크립트를 분석 대상으로 삼아 각 조각에서 20k개의 사용자/생각/응답 특징을 추출했다. 특징 임베딩은 의미 공간에서 벡터를 만들고 k-means 방식으로 클러스터링한 뒤, 각 클러스터를 대표하는 간단한 라벨을 LLN에 의해 생성한다. 이를 통해 Gemini의 행동에서 흥미로운 고수준 특징이 다수 발견되었고, 특징들 간의 상관 관계를 파악하는 데 도움이 되었다. 또한 Autorater 프롬프트의 구성을 통해 한 번의 LLM 호출만으로도 클러스터를 형성하는 프로세스의 간결성을 확보했다.
그러나 생각/응답 특성의 예측은 로지스틱 회귀와 같은 간단한 모델로도 완벽하게 예측되지는 않았다. 예를 들어 API 참조와 언급으로부터 HTTP 상태 코드와 같은 특성을 예측하는 경우가 상대적으로 잘 드러났고, 이는 예측 가능성이 높은 클러스터의 예에 해당한다. EDW와의 비교에서 LLM-주도 방식은 직관적이고 해석이 더 명확하나, 특정 통계 모델의 오차 최소화 측면에서는 EDW가 더 적합할 수 있다. 이 연구는 내부 모델 정보에 의존하지 않는 탐색적 분석의 가능성을 보여주지만, 모델 내부 제어의 직접적인 대체로 보기는 어렵다.
이미지 분석
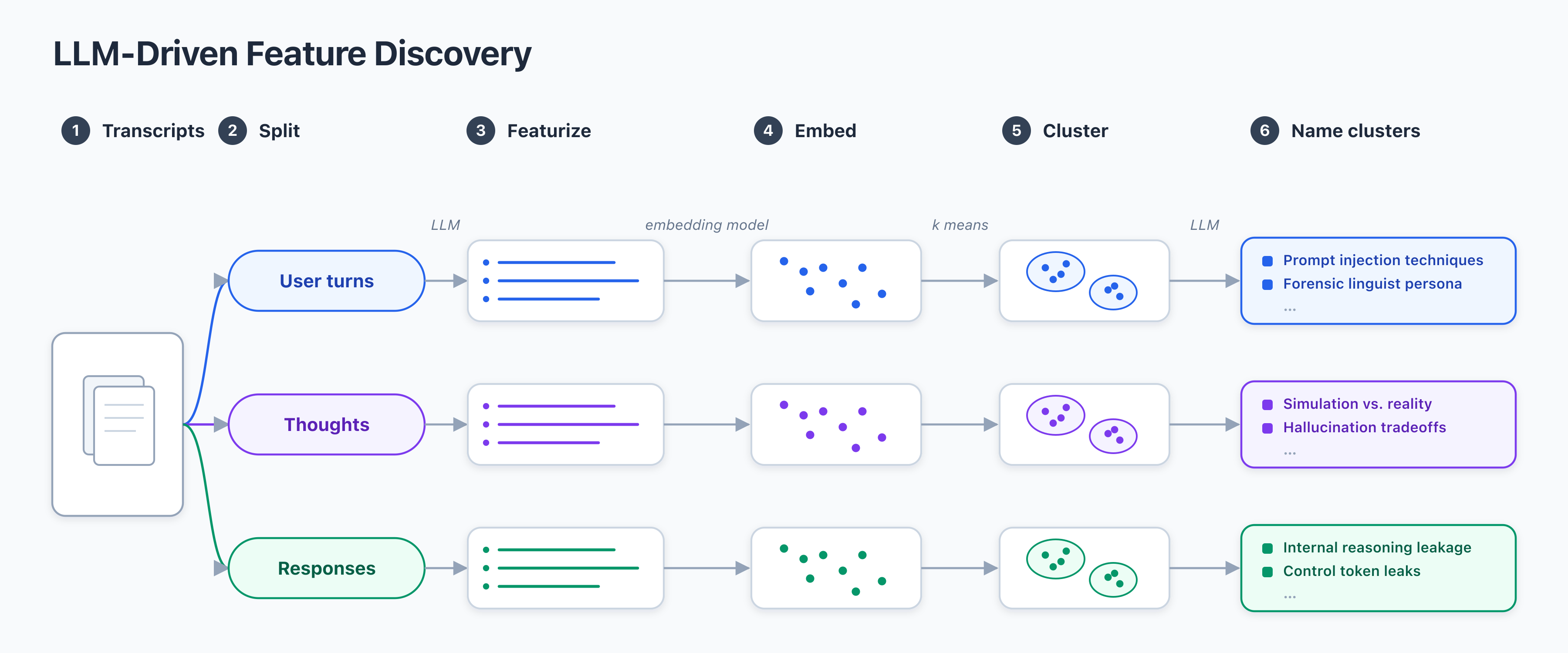
Diagram
트랜스크립트를 사용자 발화/생각/응답으로 분리하고, 임베딩-클러스터링-레이블링으로 특징을 도출하는 파이프라인의 흐름을 시각적으로 제시한다.
LLM-Driven Feature Discovery 흐름을 보여주는 다이어그램
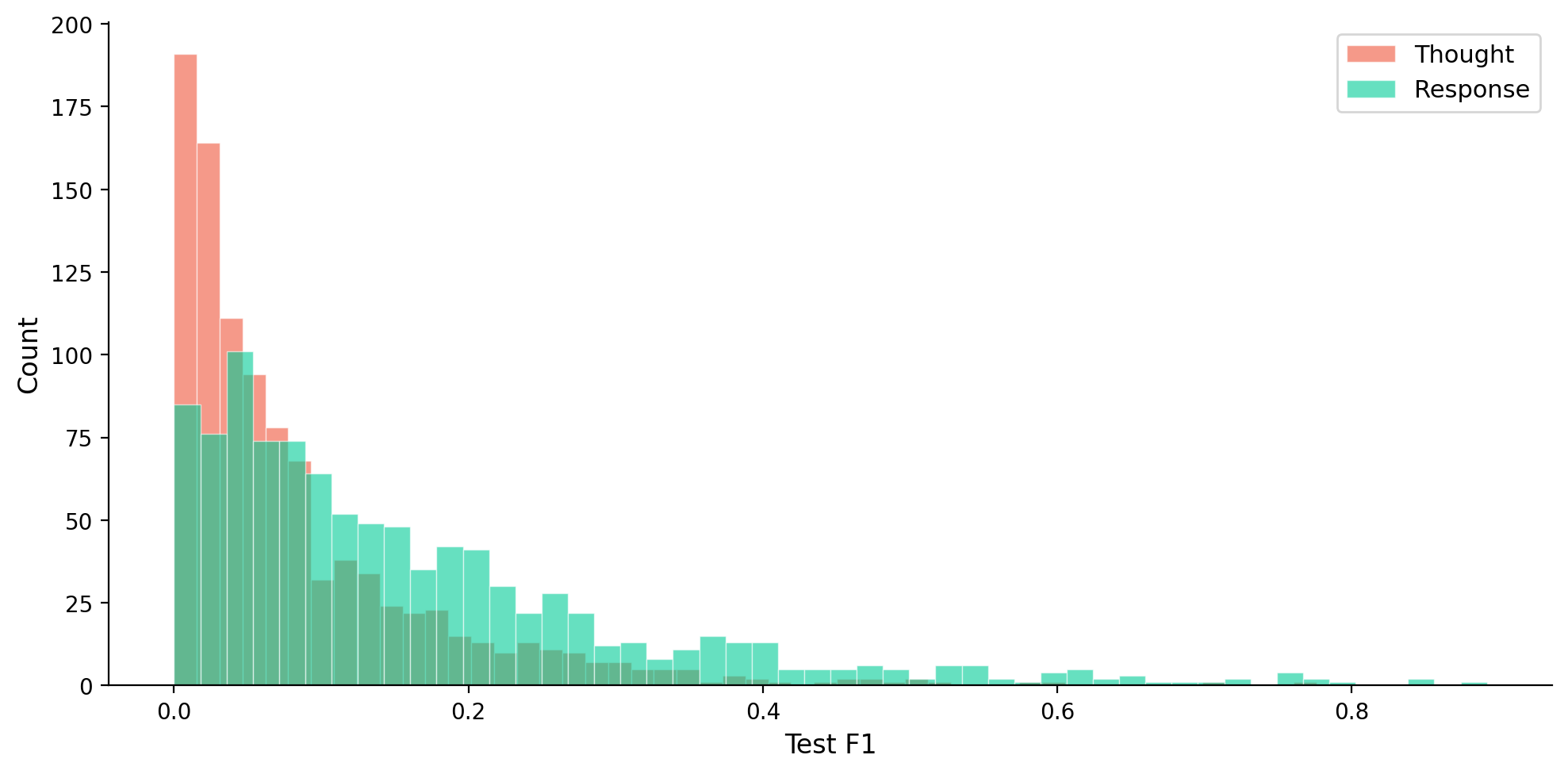
Chart
고정된 x축(Test F1)에서 Thought와 Response의 개별 카테고리별 빈도를 시각화해, 어떤 클러스터가 예측에 유의미한지 시사한다.
Thought/Response의 예측 성능 분포를 나타내는 차트
실무 Takeaway
- 대화 트랜스크립트의 각 구성요소를 자동으로 특징화하면 모델 행동의 패턴을 빠르게 포착할 수 있다
- 임베딩-클러스터링-레이블링의 간결한 파이프라인은 외부 관찰만으로도 의미 있는 주제를 도출할 수 있게 한다
- 클러스터의 예측 가능성은 특정 경우에 한정되며, API 참조 기반 특성처럼 명시적 신호가 강한 부분에서 더 잘 드러난다
- EDW와의 비교에서 각 방식의 강점이 다르므로 목적에 따라 적합한 방법을 선택해야 한다
- 향후 연구는 내부 모델 정보 의존도와 해석 가능성의 균형을 어떻게 달성할지에 중점을 둘 필요가 있다
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 23.수집 2026. 06. 23.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.