TL;DR
이 글은 HuggingFace Transformers v5의 MoE 기반 인프라 위에 NVIDIA NeMo AutoModel을 얹어 MoE 모델의 파인튜닝 처리량을 크게 끌어올리고 GPU 메모리 사용을 줄이는 방법과 성능 결과를 정량적으로 제시한다. NeMo AutoModel은 AutoModelForCausalLM을 서브클래싱해 from_pretrained() API 호환성을 유지하면서 Expert Parallelism, DeepEP fused all-to-all dispatch, TransformerEngine 커널 등 네이티브 수준의 최적화를 적용해 사용자 코드 변경을 최소화한 채 성능을 향상시킨다.
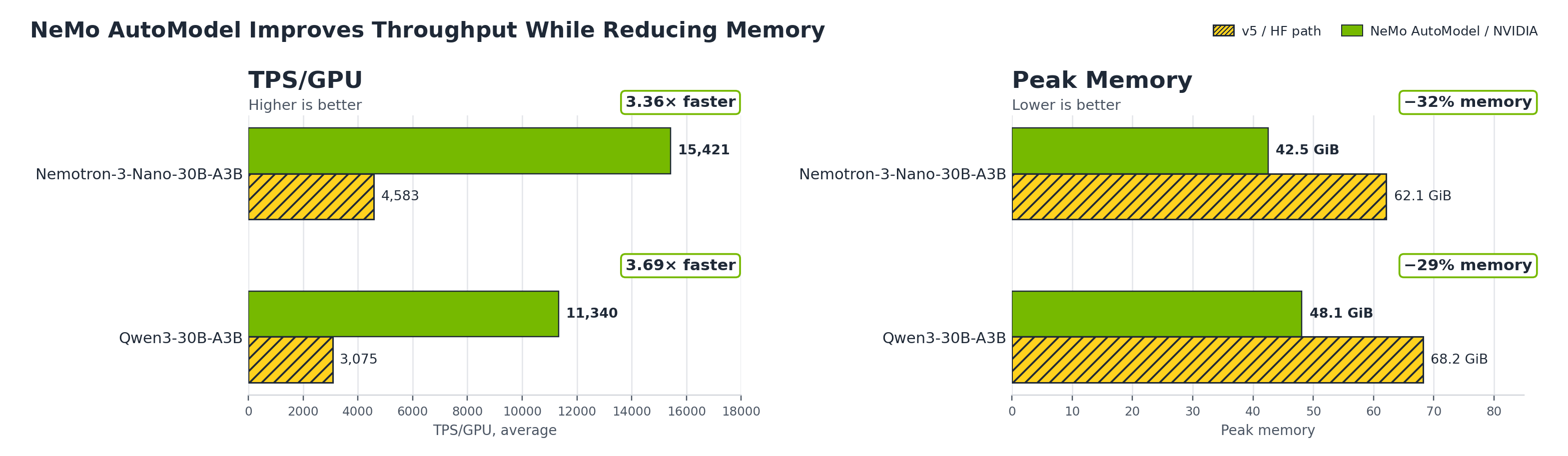
벤치마크에서 NeMo AutoModel은 single-node 8x H100 환경의 대표적 30B MoE 모델들에서 평균 TPS/GPU를 3.4~3.7배 높였고 피크 메모리는 29~32% 줄였으며, v5가 메모리 초과로 실행하지 못하는 550B 전수 파인튜닝을 Expert Parallelism으로 16노드(128 GPU) 규모에서 가능하게 했다. 성능 향상은 전문가 파라미터의 샤딩으로 메모리를 낮추는 EP, 라우팅과 통신을 연산과 겹치게 처리하는 DeepEP, 그리고 TransformerEngine의 fused 연산 커널이 결합되어 얻어진 결과이다.
이 접근법은 from_pretrained() 한 줄만 바꾸는 '제로 프릭션' 마이그레이션 경로를 제공하므로 기존 Transformers 기반 코드베이스에 최소한의 변화만으로 대규모 MoE 학습을 확장할 수 있다. 다만 최적의 이득을 보려면 H100급 GPU와 분산 설정, Balanced routing 등 MoE의 작동점을 고려한 환경 구성이 필요하며 모델별 사용자 정의 커널 적용 여부에 따라 성능 차이가 발생할 수 있다.
섹션별 상세
import os
import torch
import torch.distributed as dist
from nemo_automodel import NeMoAutoModelForCausalLM
from nemo_automodel.recipes._dist_utils import create_distributed_setup_from_config
dist.init_process_group(backend="nccl")
torch.manual_seed(0)
torch.cuda.set_device(int(os.environ.get("LOCAL_RANK", 0)))
dist_setup = create_distributed_setup_from_config(
{
"strategy": "fsdp2",
"ep_size": 8,
},
)
model = NeMoAutoModelForCausalLM.from_pretrained(
"nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16",
dtype=torch.bfloat16,
distributed_setup=dist_setup,
)
dist.destroy_process_group()이 파이썬 코드는 FSDP2와 Expert Parallelism(ep_size=8)을 설정해 NeMo AutoModel으로 사전학습된 MoE 모델을 from_pretrained() 한 줄로 로드하여 분산 학습 환경을 구성하는 예시이다.
실무 Takeaway
- NeMo AutoModel은 from_pretrained() API 호환을 유지하면서 내부에서 Expert Parallelism, DeepEP, TransformerEngine을 적용해 기존 코드 변경 없이 MoE 학습을 대폭 가속하므로 대규모 MoE 마이그레이션 비용을 낮춘다.
- Expert Parallelism으로 전문가 가중치를 전문가 차원으로 샤딩하면 per-GPU 전문가 메모리 요구량이 ep_size 배만큼 줄어들어 단일 GPU 메모리 한계로 불가능했던 대규모 전수 파인튜닝을 가능하게 한다.
- DeepEP는 라우팅 통신과 전문가 계산을 융합된 커널로 겹쳐 실행해 통신 대기 시간을 줄이고 TransformerEngine의 fused 연산은 순·역전파 모두에서 일관된 속도 향상을 제공하므로 실운영 처리량과 비용 효율을 동시에 개선한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.