TL;DR
Loka는 음성을 텍스트로 변환하는 기존 3단계 파이프라인의 지연과 정보 손실 문제를 해결하기 위해 Amazon Nova 2 Sonic을 활용한 speech-to-speech 아키텍처를 도입했다. 이 접근법은 음성 신호의 억양과 맥락을 보존하면서 입력 오디오를 모델이 직접 이해하고 음성으로 응답을 생성하도록 설계되어 대화의 자연스러움과 처리 효율을 동시에 개선한다.
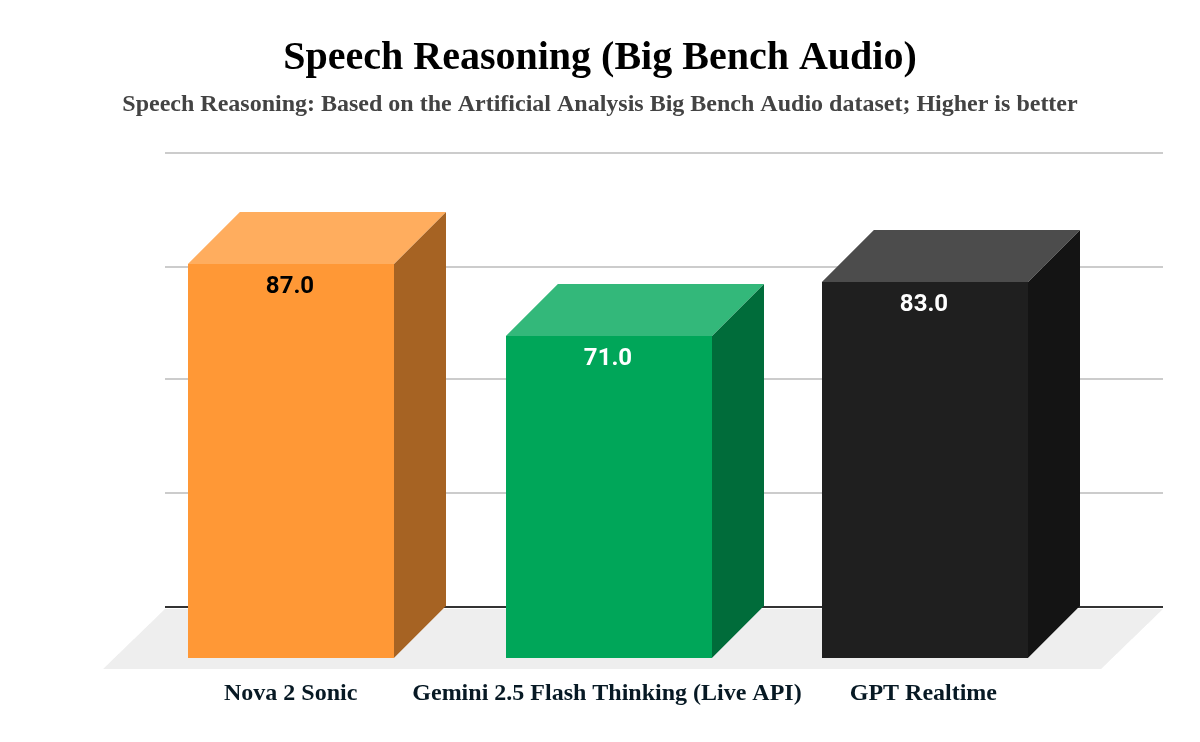
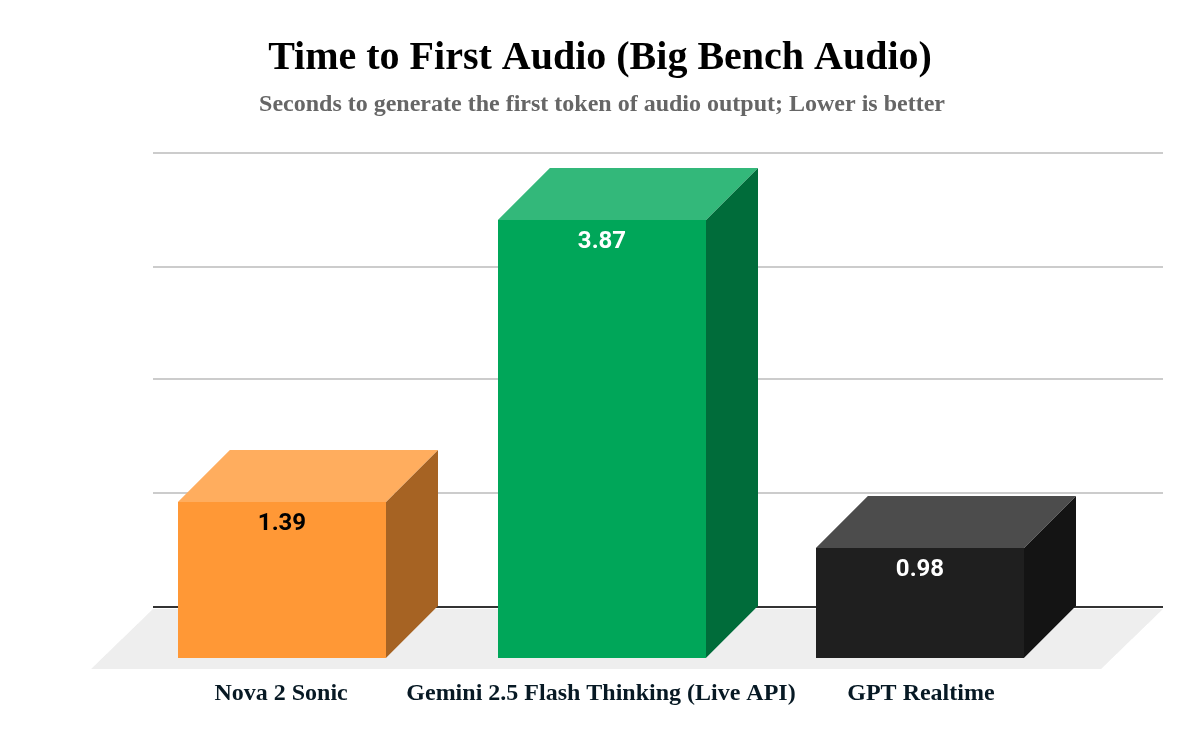
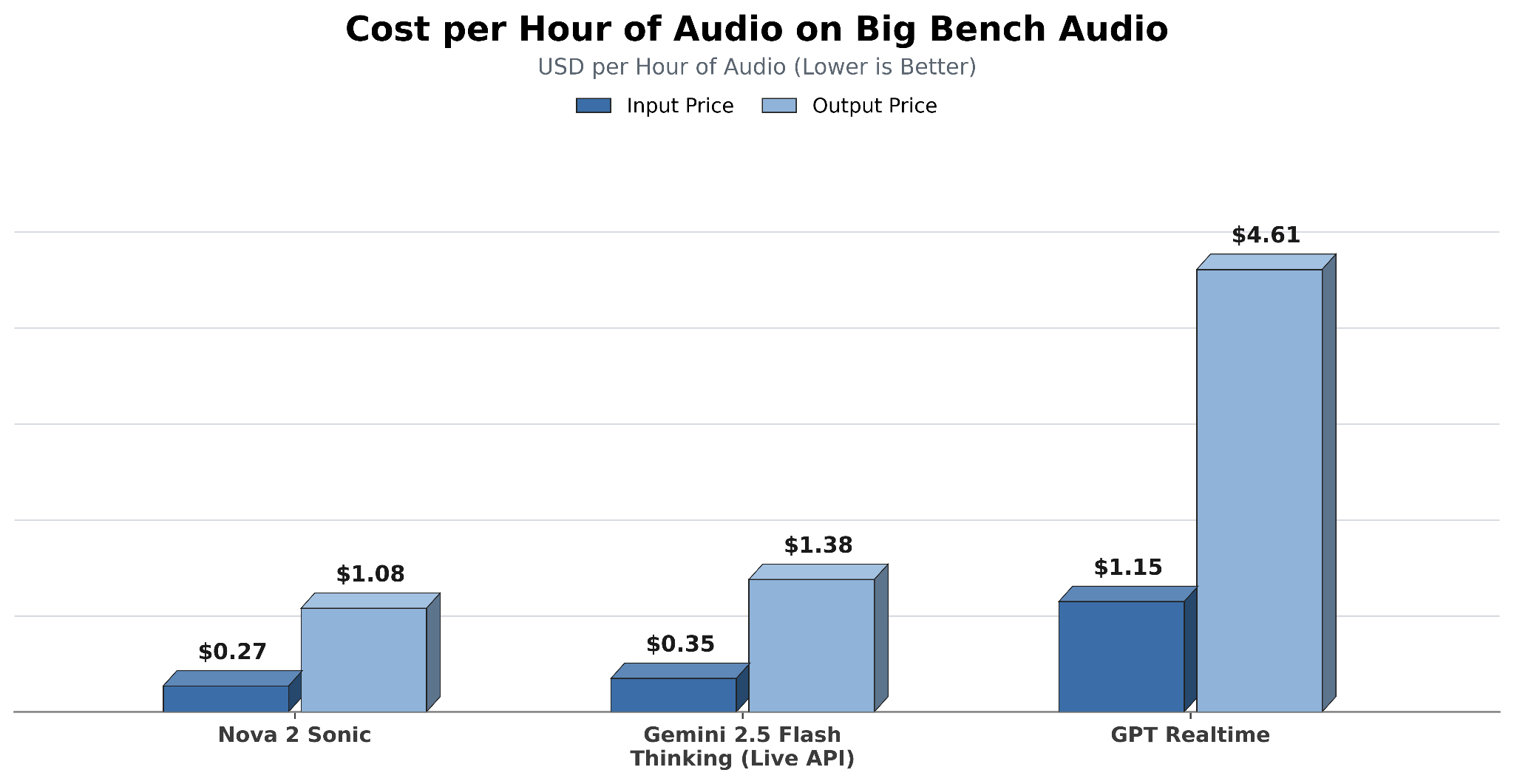
평가 결과 Nova 2 Sonic은 Big Bench Audio에서 speech reasoning 87.0을 기록했으며 Time to First Audio는 1.39초로 제시되어 기존 텍스트 기반 파이프라인보다 빠른 응답을 제공하고 비용은 시간당 약 0.27달러로 비교적 낮게 보고됐다. 프롬프트 템플릿 반복 개선을 통해 Judge 점수가 베이스라인 2.7에서 Prompt v2의 3.8까지 상승했고, 실제 고객 페르소나 테스트에서 평균 점수가 4.0으로 나타나 실무 적용성이 입증되었다.
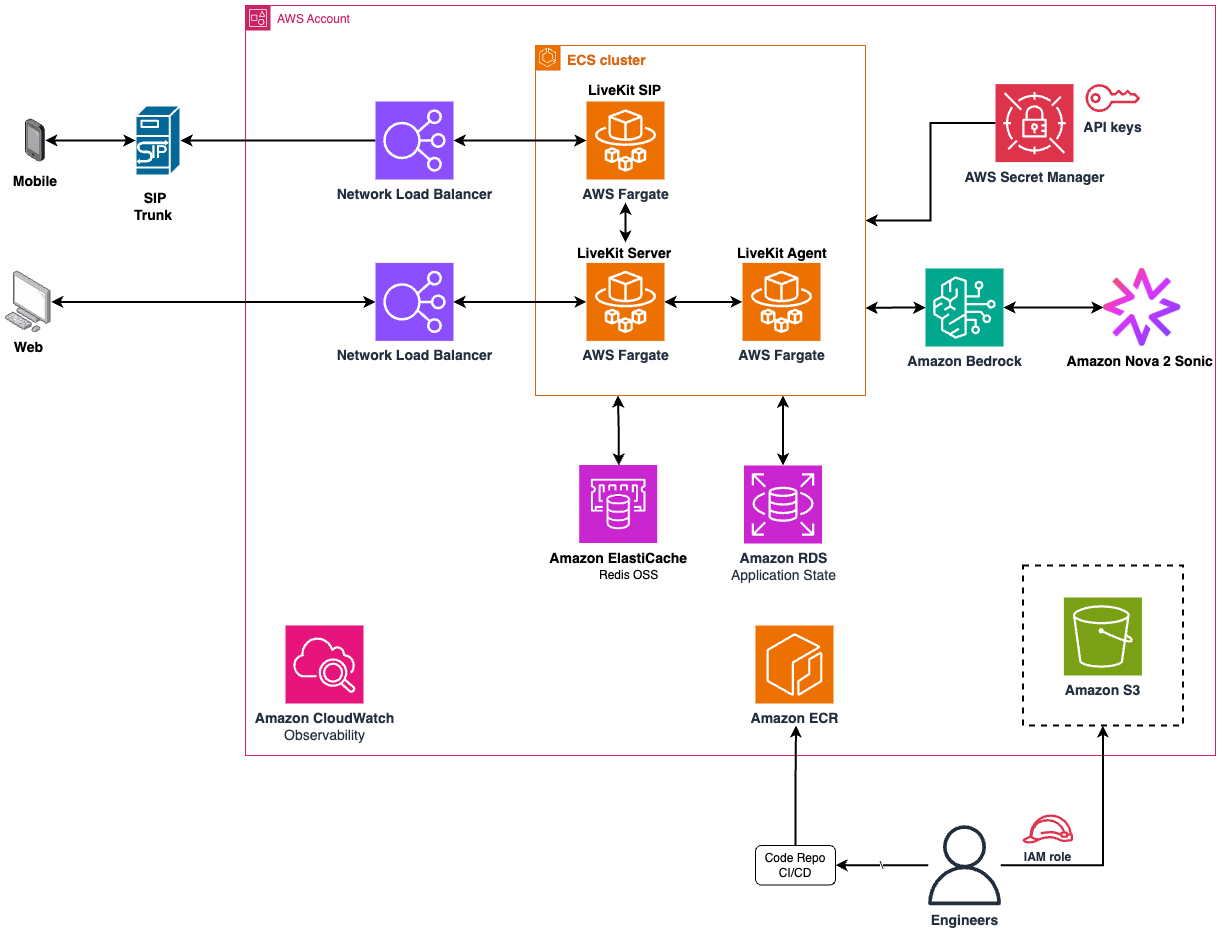
엔지니어링 관점에서는 LiveKit을 전송 계층으로, AWS Fargate·ECS·ElastiCache·RDS를 조합한 서버리스·이벤트 기반 아키텍처로 확장성과 회복력을 확보했고 Amazon Bedrock을 통해 Nova 2 Sonic을 호출하는 방식이 사용됐다. 다만 긴 산만한 발화나 고령자 페르소나에서 완성도와 오류 복구가 낮아지는 한계가 관찰되어 추가적인 프롬프트 엔지니어링과 튜닝이 필요하다.
섹션별 상세
실무 Takeaway
- 음성을 중간 텍스트로 변환하지 않는 speech-to-speech 파이프라인은 억양과 맥락 신호를 보존해 응답 자연성과 추론 정확도를 높이므로 실시간 음성 인터랙션에서 지연과 정보 손실을 동시에 줄일 수 있다.
- 프롬프트를 템플릿화하고 구체적 행동 예시와 체크리스트를 포함해 반복적으로 개선하면 모델의 Completeness와 Conversational Naturalness 점수를 계량적으로 향상시켜 복잡한 고객 요청을 한 회화 내에서 해결할 확률을 높일 수 있다.
- 운영 환경에서는 WebRTC/SIP 전송을 LiveKit에 위임하고 AWS Fargate·ElastiCache·RDS로 세션·상태 관리를 분리하면 미디어 처리와 비즈니스 로직의 독립적 확장으로 대규모 지점에 대한 비용·성능 관리가 수월해진다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.