TL;DR
보험 중개업계는 전 세계적으로 8조 달러 규모임에도 신청서 작성, 보장 분석, 시스템 간 재입력 등 반복적 백오피스 업무 때문에 인력 부족과 운영병목을 겪고 있다. 범용 AI는 업계 특유의 PII·재무·인수 데이터와 규제 요구를 충족시키기 어렵기 때문에 도메인 특화된 처리와 검증 가능한 파이프라인이 필요하다. Cara는 이러한 문제를 해결하기 위해 AWS 위에 설계된 AI 네이티브 플랫폼으로, Amazon EKS에서 마이크로서비스를 멀티 AZ로 운영하며 각 조직을 네임스페이스로 격리해 수천 건의 동시 워크플로를 지원한다. 데이터는 ingestion 파이프라인으로 정규화되어 LLM 추론(coverage/quote intelligence, 신청서 자동완성, 제안서·갱신 생성 등)에 입력되고, 추론은 Amazon Bedrock의 관리형 API로 수행되어 GPU 인프라 관리를 생략한다. 이 설계는 인프라 운영 부담을 줄이고 규제·보안 요구를 충족시키며 중개사의 처리량을 늘리는 효과를 제공한다. 다만 보험사별 요구사항·양식의 정확한 매핑과 PII 보호를 위한 엔드투엔드 검증이 계속 필요하며, 본문에서는 구체적 수치(예: 비용·정확도 개선 폭)가 제시되지 않아 실효성 판단을 위해서는 도입 사례의 추가 데이터가 요구된다.
섹션별 상세
실무 Takeaway
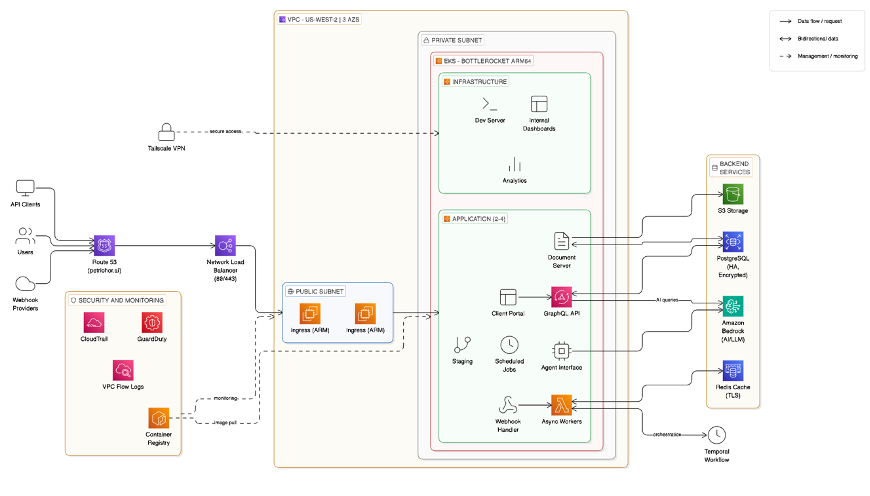
- 보험 중개사의 반복적 문서 작업을 자동화하려면 ACORD 같은 업계 표준 양식과 보험사별 요구사항을 입력으로 받아 정확히 매핑·검증하는 파이프라인이 필요하다 — Cara는 원문서와 이전 제출 자료를 전처리해 LLM에 입력하고 cross-fill로 결과를 생성한다.
- 대규모 동시 사용자를 지원하려면 Kubernetes 기반 오케스트레이션(Amazon EKS)으로 마이크로서비스를 멀티 AZ에 분산하고 테넌트 네임스페이스로 격리해야 한다 — 이 방식은 수천 동시 워크플로를 처리하는 신뢰성·보안 요구를 충족한다.
- LLM 추론은 Amazon Bedrock의 관리형 API를 활용해 GPU 인프라 관리를 생략하고도 고품질 추론을 얻을 수 있다 — 인프라 운영 부담을 줄이며 보안·컴플라이언스 통합에 집중할 수 있다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.