TL;DR
이번 글은 OpenAI가 발표한 GPT-5.6의 공개와 그에 대한 성능 및 안전성 평가를 중심으로 전개되었다. 발표는 제한적 접근으로 이루어졌으며 모델은 특정 코딩 에이전트 과제에서 높은 성과를 보였고 벤치마크에서 상위권 점수를 기록했다. 발표 배경에는 Anthropic-Fable 협상과 Mythos 통제 완화가 얽혀 있어 배포 결정이 안전성 검증과 연동되었음이 확인된다.
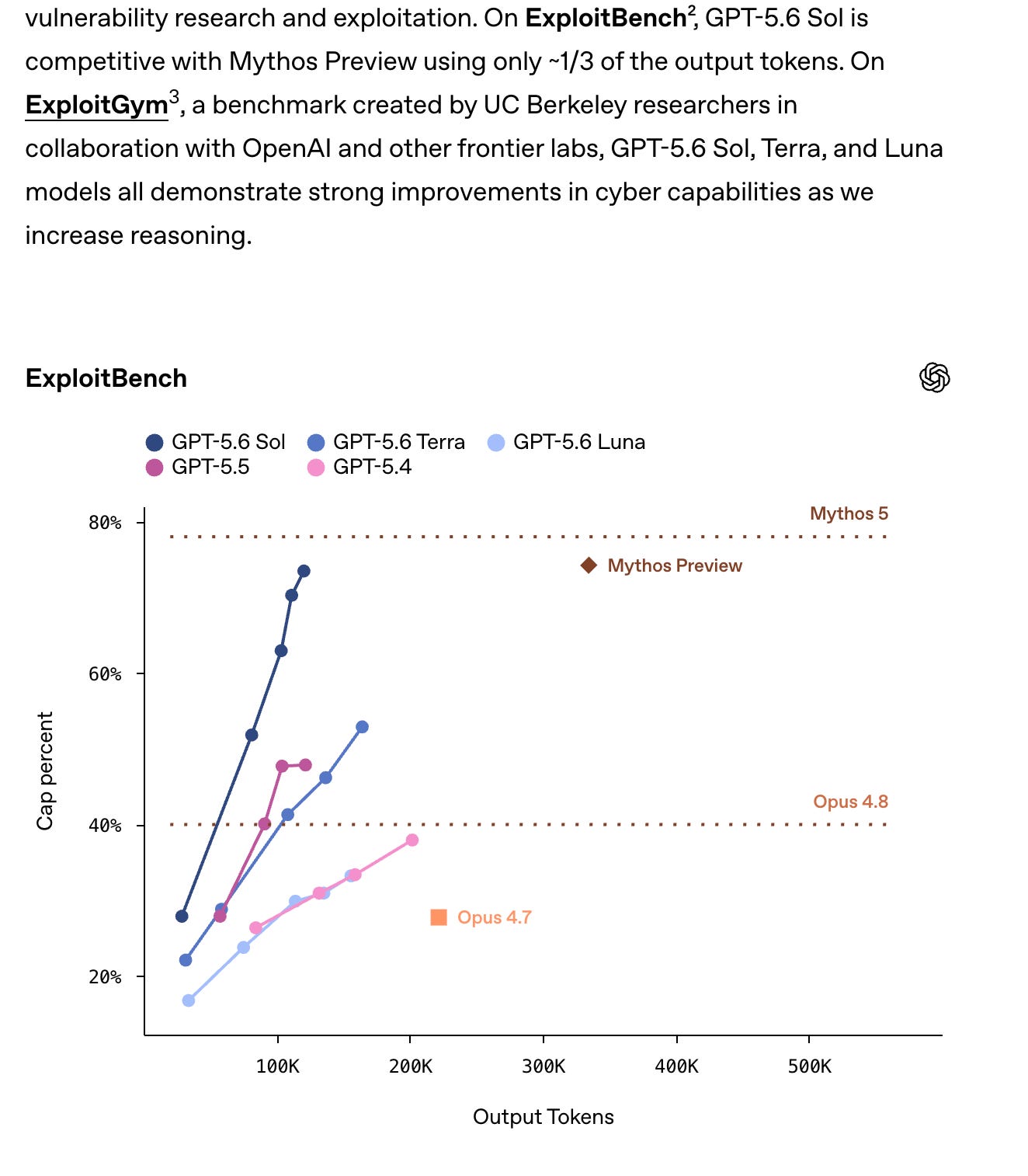
사이버 안전성 관점에서는 Preparedness Framework를 사용한 평가가 이루어져 GPT-5.6 Sol이 익스플로잇 프리미티브를 식별하는 능력을 보였으나 완전한 체인형 익스플로잇을 자율 생성하지 못해 Cyber Critical 임계값을 넘지 못했다. Chromium과 Firefox를 대상으로 한 실제 테스트에서의 관찰이 이러한 결론의 근거가 되었으며 이는 모델이 탐지·보조 역할에서 유용하지만 독립적 악용 능력으로 직결되지는 않는다는 점을 드러낸다. 이 결과는 모델 거버넌스와 액세스 통제의 필요성을 뒷받침한다.
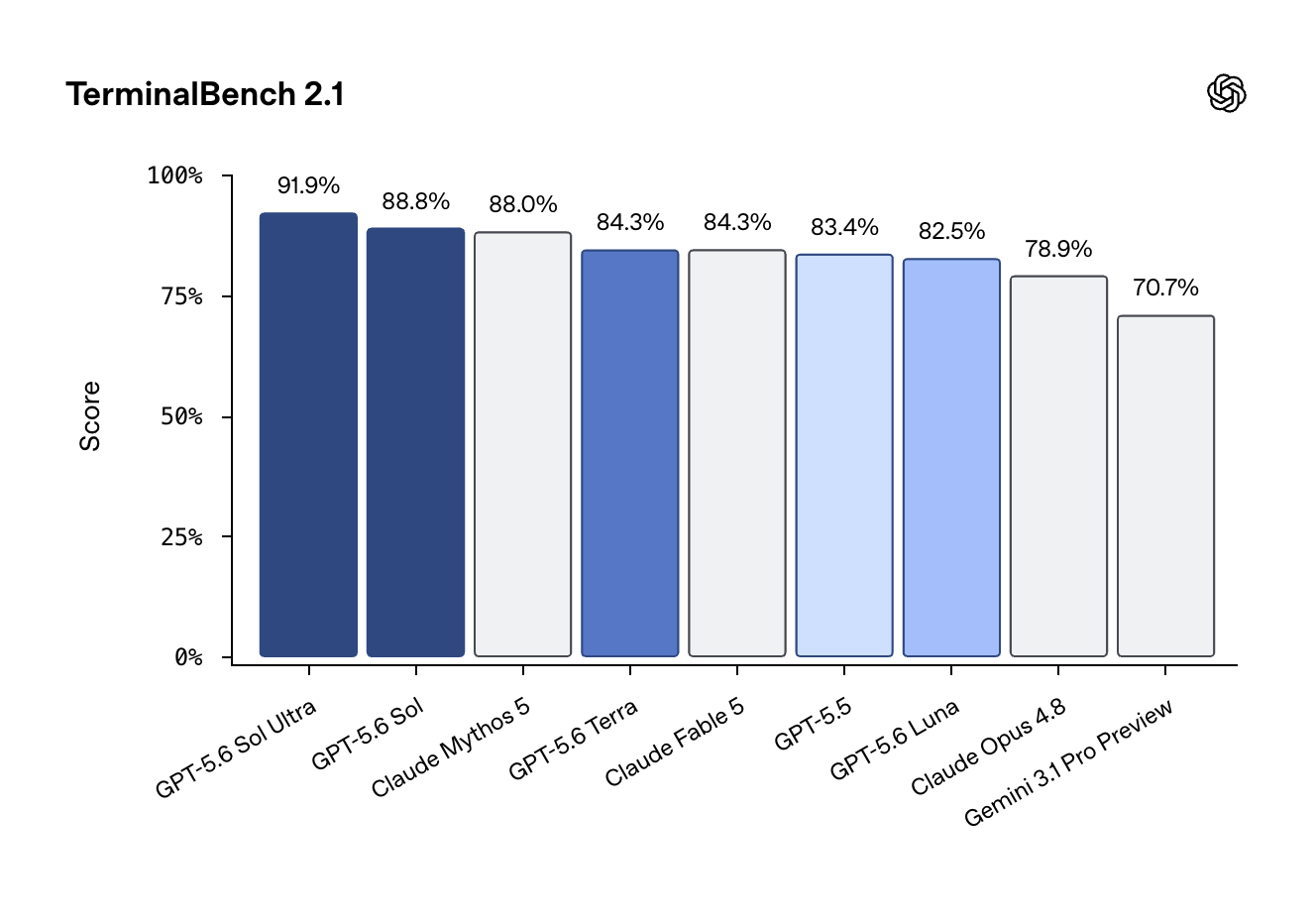
제시된 벤치마크 자료는 성능 수치뿐 아니라 출력 토큰 대비 효율성 차이를 보여주어 실무적 트레이드오프를 드러냈다. TerminalBench에서는 최고 점수가 91.9% 수준으로 보고되었고 ExploitBench 산점도는 GPT-5.6 Sol이 Mythos Preview와 유사한 성능을 더 적은 토큰으로 달성한 사례를 보였다. 따라서 실제 배포·운영 환경에서는 단순한 점수뿐 아니라 출력 토큰 비용, 안전 임계값, 모델의 프리미티브 식별 성향을 함께 고려해야 한다.
섹션별 상세
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.