TL;DR
이 글은 로컬에서 실행되는 완전한 코딩 에이전트 스택을 구축하는 튜토리얼로, 오픈 웨이트 LLM을 로컬 inference 런타임에 호스팅하고 그 위에서 파일 읽기·수정·명령 실행·검증을 수행하는 코딩 하니스를 운영하는 방법을 제시한다. 구성은 모델이 추론 및 코드 생성을 담당하고 중앙의 런타임 서버가 모델 호출과 리소스 관리를 담당하며 하니스가 생성된 코드 조각을 실제 파일 변경과 테스트 검증으로 연결하는 방식으로 작동한다. 이러한 아키텍처는 민감한 코드의 외부 유출을 차단하고 시스템을 투명하게 제어할 수 있게 하며 커스터마이즈와 내부 감사가 가능한 장점을 제공한다.
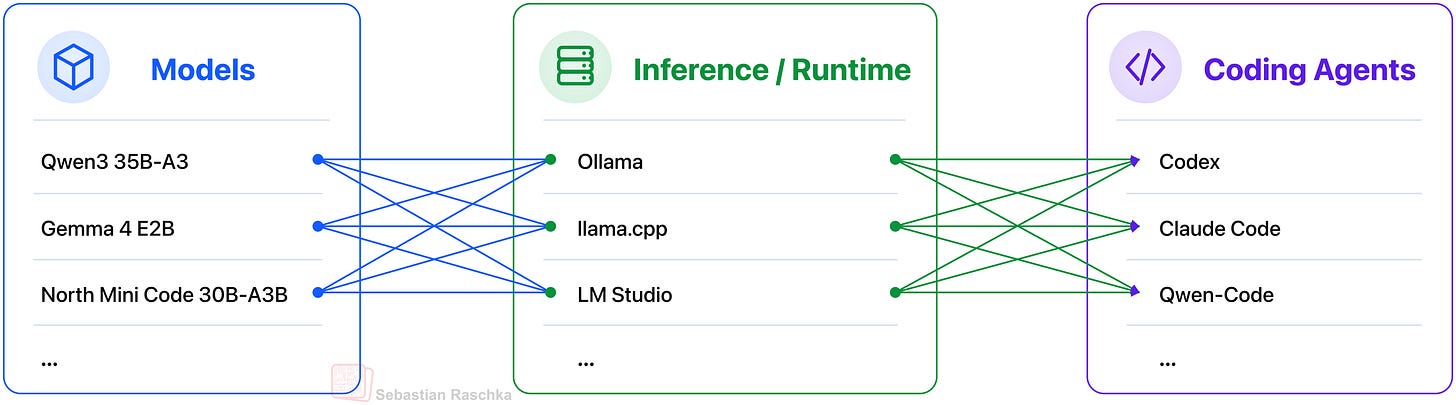
하니스는 모델 출력물을 실제 작업으로 전환하기 위해 파일 I/O, 쉘 명령 실행, 자동화된 테스트 같은 운영적 권한을 갖추어야 하고 런타임은 로컬 모델의 토큰 생성·배치·동시성 제어를 책임진다. 도식은 모델군, 런타임, 에이전트 간의 인터페이스를 명확히 구분해 보여주며 이는 에이전트의 작동 경로와 검증 포인트를 설계하는 데 직접적인 가이드가 된다. 저자는 상용 서비스인 Codex와 Claude Code를 일상적으로 병행 사용하고 있으나 로컬 스택이 제공하는 통제성과 투명성 때문에 로컬 대안의 가치가 높다고 언급했다.
로컬 구축은 운영·하드웨어 부담과 클라우드 편의성 사이의 트레이드오프가 존재하므로 실제 도입 시에는 비용 구조와 유지보수 역량을 고려해야 한다. 검증 메커니즘을 하니스에 내장하면 모델 제안의 안전성을 확보할 수 있으며 필요에 따라 상용 서비스와 로컬 스택을 병행해 편의성과 통제성의 균형을 맞출 수 있다. 전체적으로 본 튜토리얼은 로컬 환경에서 프로덕션급 코딩 에이전트를 운영하기 위한 구조적 지침을 제공한다.
섹션별 상세
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.