이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
스캔된 연감 페이지는 이름과 사진이 인쇄되어 있지만 기계 판독 가능한 연결이 없어 두 단계 모델 파이프라인을 구축해 문제를 해결했다. 첫 단계에서 Amazon Nova 2 Lite가 단일 Converse 호출로 사진 바운딩박스와 보이는 이름의 좌표, 페이지 메타데이터를 반환하고 출력 범위를 이름으로 제한해 토큰 사용량을 페이지당 약 1,000토큰으로 유지했다. 두 번째 단계에서 Claude Sonnet 4.6이 Nova 결과와 원본 이미지를 결합해 레이아웃 변동을 처리하면서 이름-얼굴 매칭을 수행했고 총 336페이지 처리로 3,122개의 매칭을 생성해 93%가 0.95 이상의 신뢰도를 얻었다. 이 구성은 복잡한 공간적 판단을 상위 모델에만 위임해 정확도를 유지하면서도 단일 모델 접근법보다 페이지당 비용을 크게 낮추는 트레이드오프를 제시한다.
섹션별 상세
연감 한 페이지는 인쇄된 이름 176개와 사진 4장이 존재하지만 기계 판독 가능한 연결 구조가 없어서 이름과 얼굴을 자동 연결하는 문제가 발생했다. 이 문제를 해결하기 위해 두 개의 서로 다른 모델을 연속 파이프라인으로 구성했고 첫 단계에서 이미지의 사진 바운딩박스와 보이는 이름의 좌표를 추출한 뒤 두 번째 단계에서 그 결과를 바탕으로 어떤 이름이 어떤 얼굴과 대응하는지 판단하도록 했다. 실험 결과 336개 페이지 처리로 3,122개의 이름-얼굴 매칭을 생성했으며 그중 93퍼센트가 0.95 이상의 신뢰도 점수를 받았다. 이 접근법은 레이아웃 변동이 큰 문서에서 정확도를 유지하면서 처리 비용을 낮추는 실무적 이점을 제공한다.
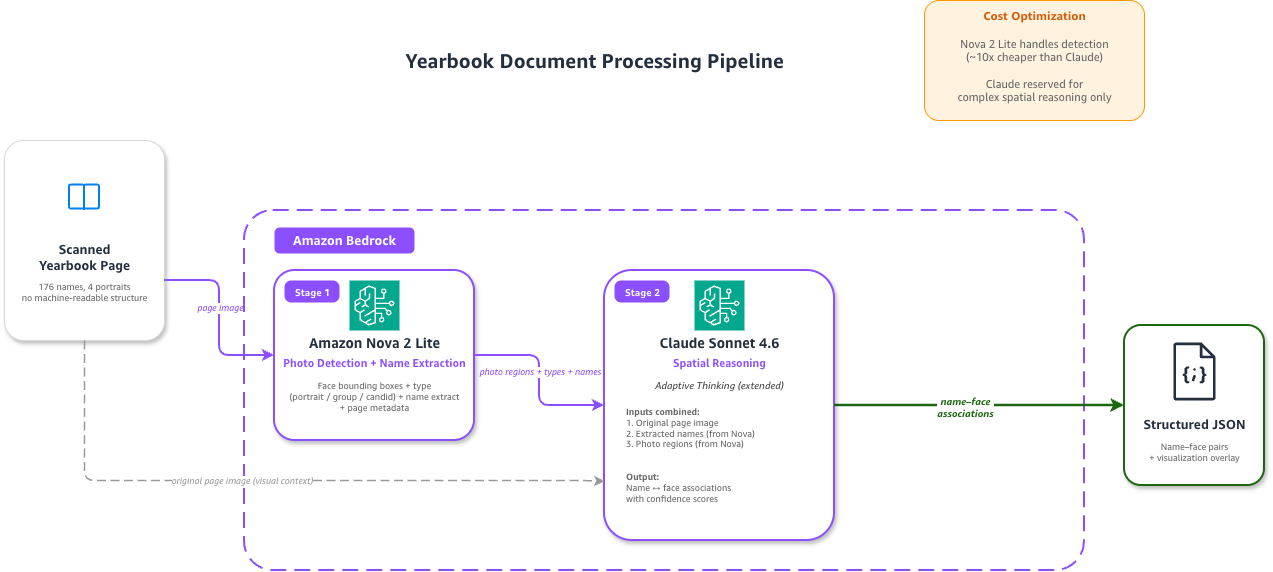
첫 단계는 Amazon Nova 2 Lite가 담당했고 한 번의 Converse API 호출로 사진 감지·분류, 페이지에 보이는 이름과 그 근사 위치, 페이지 수준 메타데이터를 반환했다. 이 단계에서는 reasoning_config를 LOW로 설정해 추론 수준을 낮추었고, 이름만 추출하도록 출력 범위를 제한함으로써 출력 토큰을 페이지당 약 1,000토큰 수준으로 유지했다. 전체 OCR을 대신해 모든 텍스트 토큰을 반환하면 대략 4,500토큰이 예상되므로 필요한 정보만 추출하는 전략이 비용과 토큰 사용량을 크게 절감했다. 결과적으로 첫 단계는 경계 탐지와 최소한의 텍스트 추출을 저비용으로 수행하는 역할을 맡았다.
두 번째 단계에서는 Claude Sonnet 4.6이 Nova의 이름-위치 결과와 사진 바운딩박스를 입력으로 받아 공간 추론을 수행해 이름과 얼굴을 연결했다. 이 단계는 원본 페이지 이미지와 추출된 엔티티 좌표를 결합해 레이아웃 변동성을 처리하는 로직을 수행했고 Claude 쪽에서는 reasoning을 제어하는 필드명이 thinking으로 별도 관리됐다. 실험에서 LOW, MEDIUM, HIGH 같은 추론 수준 사이에 구조화된 추출 정확도 차이는 의미 있게 나타나지 않아 비용이 낮은 설정을 선택했다. 이 구성은 복잡한 공간 판단만을 상위 모델에 위임함으로써 단일 모델에 전 작업을 맡겼을 때보다 페이지당 비용을 약 2/3 절감하는 것으로 보고되었다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 30.수집 2026. 06. 30.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.