이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
IBS Software는 영어와 일본어가 혼재된 화물 운송 이메일에서 23개 엔티티를 추출하기 위해 Amazon Bedrock의 토큰 기반 지식 증류를 활용해 대형 교사 모델의 토큰 예측을 학생 모델에 전달하는 파이프라인을 설계했다. 입력으로 .eml 이메일을 프롬프트 템플릿과 JSON 변환을 거쳐 S3에 적재하고 Bedrock에서 Nova Pro로부터 Nova Lite로 증류하여 더 작고 빠른 학생 모델을 얻었다는 점이 핵심이다. 학습은 500건의 라벨링된 이메일(영어 350, 일본어 150)을 사용해 학생 모델을 4 epochs·70 스텝으로 학습시켰고 손실은 0.05에서 0.008로 줄었으며 테스트 F1은 95.085%로 보고되었다. 이 결과는 실시간 .eml 처리 파이프라인과 Bedrock 배포로 운영 지연을 낮춘 채 비용을 약 14배 절감한 실제 생산 환경 적용 사례이다.
섹션별 상세
화물 운송 이메일은 AWB, 항공편, 무게, 취급 지시 등 다수의 도메인 속성을 포함하고 영어와 일본어가 혼재되어 있어 단일 모델로 높은 정확도와 저비용을 동시에 확보하기 어려웠다. 입력으로 .eml 형식의 원시 이메일을 받아 프롬프트 템플릿으로 엔티티 추출 형식을 맞추고 JSON으로 변환한 뒤 S3에 저장하여 Bedrock의 토큰 기반 증류 파이프라인에 전달하는 방식으로 처리 파이프라인을 설계했다. 이 파이프라인은 대형 교사 모델의 토큰별 예측을 학생 모델이 모사하도록 학습시키는 구조로, 결과적으로 더 작고 빠른 모델을 얻어 실시간 추론 요구를 충족하게 한다. 다국어 문서 처리와 실시간 응답이라는 두 축의 요구를 동시에 맞추기 위해 입력 전처리와 포스트프로세싱에서 언어별 규칙을 적용했다.
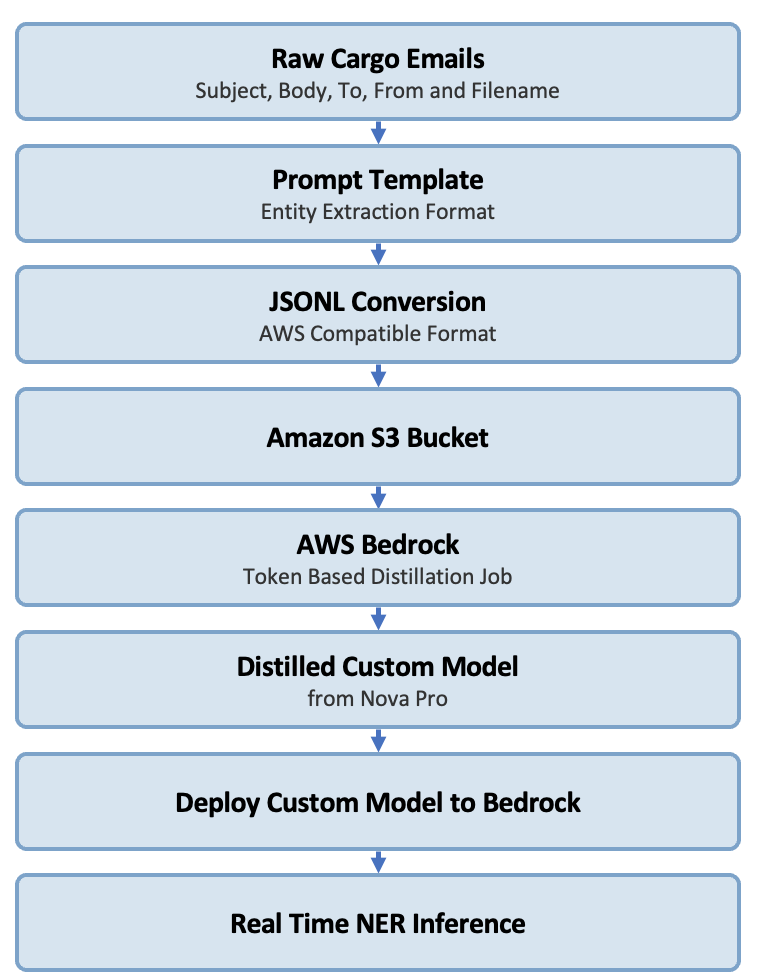
프로젝트 실행은 데이터 수집과 주석 단계에서부터 모델 학습·증류·배포까지 약 4개월이 소요되었으며 팀은 아홉 명으로 구성되어 있었다. 구체적으로 500개의 이중언어 이메일(영어 350건, 일본어 150건)을 23개 엔티티로 주석했고 PyTorch 및 TextBrewer 같은 오픈소스 프레임워크에서의 난제를 거친 뒤 Amazon Bedrock을 통해 Nova Pro 교사 모델로부터 Nova Lite 학생 모델을 증류했다. 학습 과정은 학생 모델을 4 epochs, 총 70 스텝으로 학습시켰고 손실은 0.05에서 0.008로 감소했으며 테스트에서 95.085 퍼센트 F1을 확보해 품질을 입증했다. 이 성과는 실시간 .eml 처리 파이프라인과 Bedrock 배포를 통해 운영 환경에서 저지연으로 동작하면서 비용은 14배 절감한 것으로 보고되었다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 07. 01.수집 2026. 07. 01.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.