이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
이미지로 제공된 A-CODE-LLM Bench의 막대그래프는 여러 모델의 Overall Score를 수치화해 비교한 결과를 보여주며, 최고 77.2점과 최저 44.5점 사이에 약 32.7포인트의 성능 격차가 확인된다. 그래프는 중간 구간에 점수가 밀집한 모델 그룹과 상위권 모델 간의 구분을 동시에 드러내어 모델 선택 시 단순 종합 점수 외에 세부 태스크별 성능 검토가 필요함을 시사한다. 다만 이미지에는 벤치마크의 구체적 평가 항목과 가중치가 포함되어 있지 않아 정확한 원인 분석과 적용 가능성 판단을 위해서는 원문 또는 벤치마크 문서의 추가 확인이 요구된다.
실용적 조언
- 이미지의 종합 점수만으로는 특정 태스크에 대한 성능 보증이 부족하므로 벤치마크의 세부 평가 항목과 데이터셋 구성을 확인할 필요가 있다. 세부 지표를 확인하면 모델 간 근소한 점수 차이가 실제 응용에서 의미 있는 차이로 연결되는지를 판단할 수 있다. 또한 모델 선택 시 응답 지연·비용·추론 환경 등 운영 요소와의 균형을 함께 고려해야 한다.
섹션별 상세
A-CODE-LLM Bench라는 제목의 막대그래프가 게시물 이미지로 제공되며 각 모델의 Overall Score가 수치로 표기되어 있다. 상위 바는 77.2부터 시작하고 하위 바는 44.5로 끝나는 것을 이미지에서 직접 확인할 수 있다. 이런 시각 자료는 모델 간 상대적 성능을 한눈에 비교할 수 있게 하며 숫자 기반의 근거를 함께 제시한다.
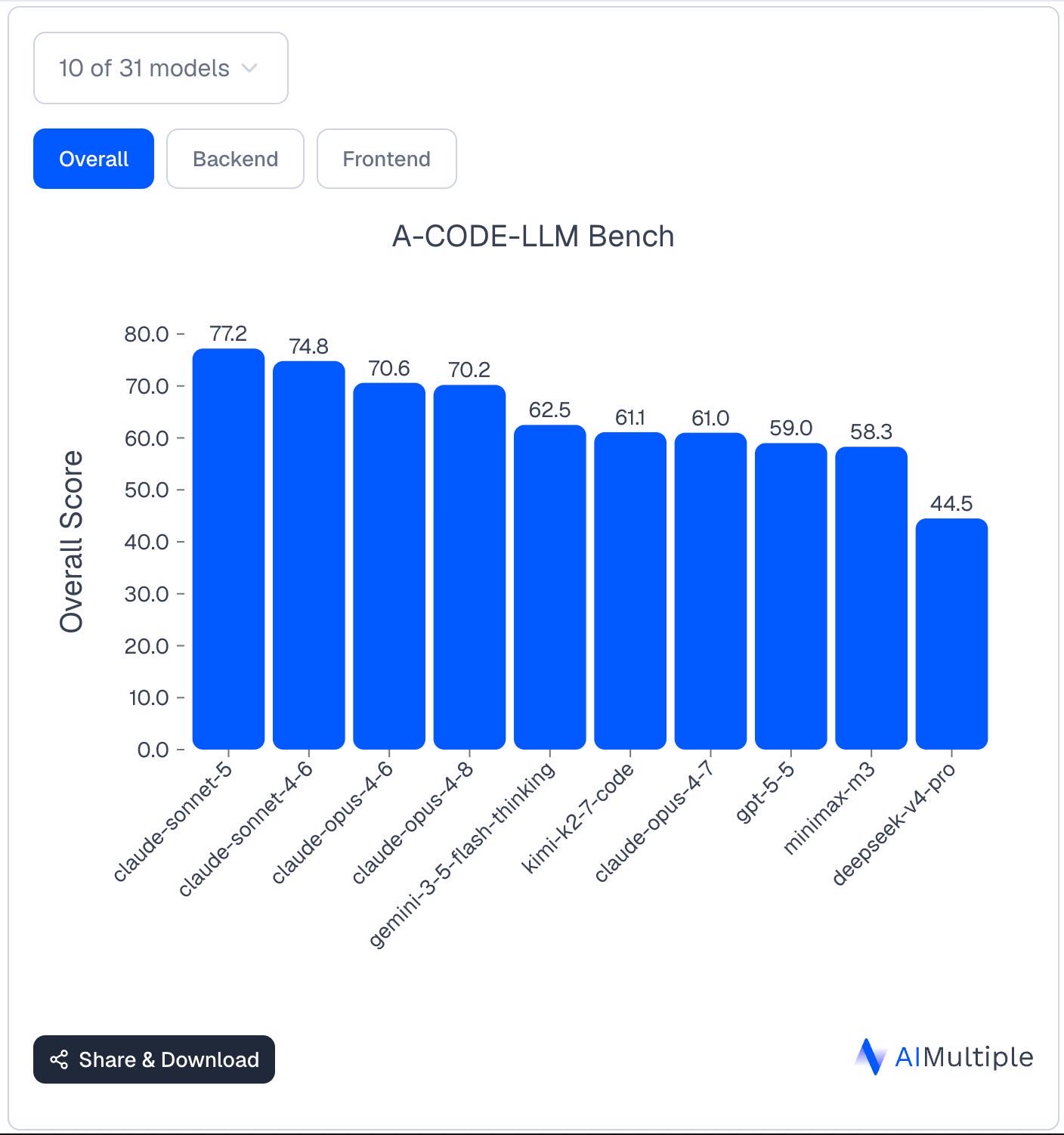

이미지에 나타난 점수 분포는 상위권과 하위권 사이에 상당한 격차가 있음을 드러낸다. 최고 점수와 최저 점수 사이의 차이가 약 32.7포인트로 집계되어 특정 모델이 다른 모델 대비 일관되게 우수한 성능을 보였음을 의미한다. 이러한 격차는 모델 선택 시 성능 차이를 고려해야 함을 시사한다.
중간 구간에 여러 모델이 밀집해 있어 상위권과 하위권 사이에 비교적 유사한 성능 그룹이 존재한다는 사실이 이미지에서 확인된다. 수치가 59.0, 58.3, 61.0, 61.1, 62.5 등으로 근접하게 분포하는 구간이 있어 세부 태스크나 응용 환경에 따라 순위가 뒤바뀔 가능성이 남아 있다. 따라서 종합 점수뿐만 아니라 특정 응용에 대한 하위 지표를 추가로 확인해야 실무 적용 판단이 가능하다.
이미지 자체는 모델명 옆에 수치 라벨을 병기해 시각적 근거를 제공하나 벤치마크의 세부 방법론이나 개별 태스크 구성은 이미지에서 확인되지 않는다. 결과 해석을 위해서는 데이터셋 구성, 평가 지표, 가중치 배분 등 원문이나 벤치마크 문서의 추가 정보가 필요하다. 따라서 이 이미지는 모델 간 상대 비교의 기초 자료로 유용하지만, 결론을 내리려면 상세한 평가 조건의 확인이 선행되어야 한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 07. 01.수집 2026. 07. 01.출처 타입 REDDIT
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.