이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
NVIDIA는 개인용 AI 에이전트 구동을 위해 설계된 새로운 Windows PC 플랫폼인 RTX Spark를 공개했다. 이 플랫폼은 1 페타플롭의 AI 연산 성능과 128GB 통합 메모리를 제공하며, Windows 보안 프리미티브와 결합된 OpenShell 런타임을 통해 안전한 로컬 에이전트 환경을 지원한다. 또한 llama.cpp와 vLLM의 추론 최적화, Adobe 및 Blender 등 주요 소프트웨어와의 협업을 통해 에이전트 및 창작 워크플로의 성능을 대폭 향상했다.
대상 독자
AI 개발자 및 로컬 환경에서 고성능 AI 에이전트를 구동하려는 전문가
의미 / 영향
NVIDIA의 RTX Spark 플랫폼은 로컬 하드웨어와 보안 런타임을 결합하여 기업용 데이터 센터 수준의 AI 성능을 개인용 PC로 확장한다. 이는 개인정보 보호가 필수적인 에이전트 서비스의 대중화를 가속화할 전망이다.
섹션별 상세
RTX Spark는 1 페타플롭의 AI 연산 성능과 128GB 통합 메모리를 갖춘 Windows PC로, 로컬 환경에서 개인용 AI 에이전트를 안전하고 효율적으로 구동한다.
NVIDIA OpenShell 런타임은 Windows 보안 프리미티브를 활용해 에이전트의 정책 관리, 데이터 격리, 개인정보 보호 기능을 제공하며 Hermes Agent와 OpenClaw 등 주요 에이전트 앱에 통합된다.
llama.cpp는 다중 토큰 예측(MTP)과 텐서 병렬 처리를 통해 Qwen 3.6-27B 모델에서 최대 2배, 35B 모델에서 1.6배의 처리량 향상을 달성했다.

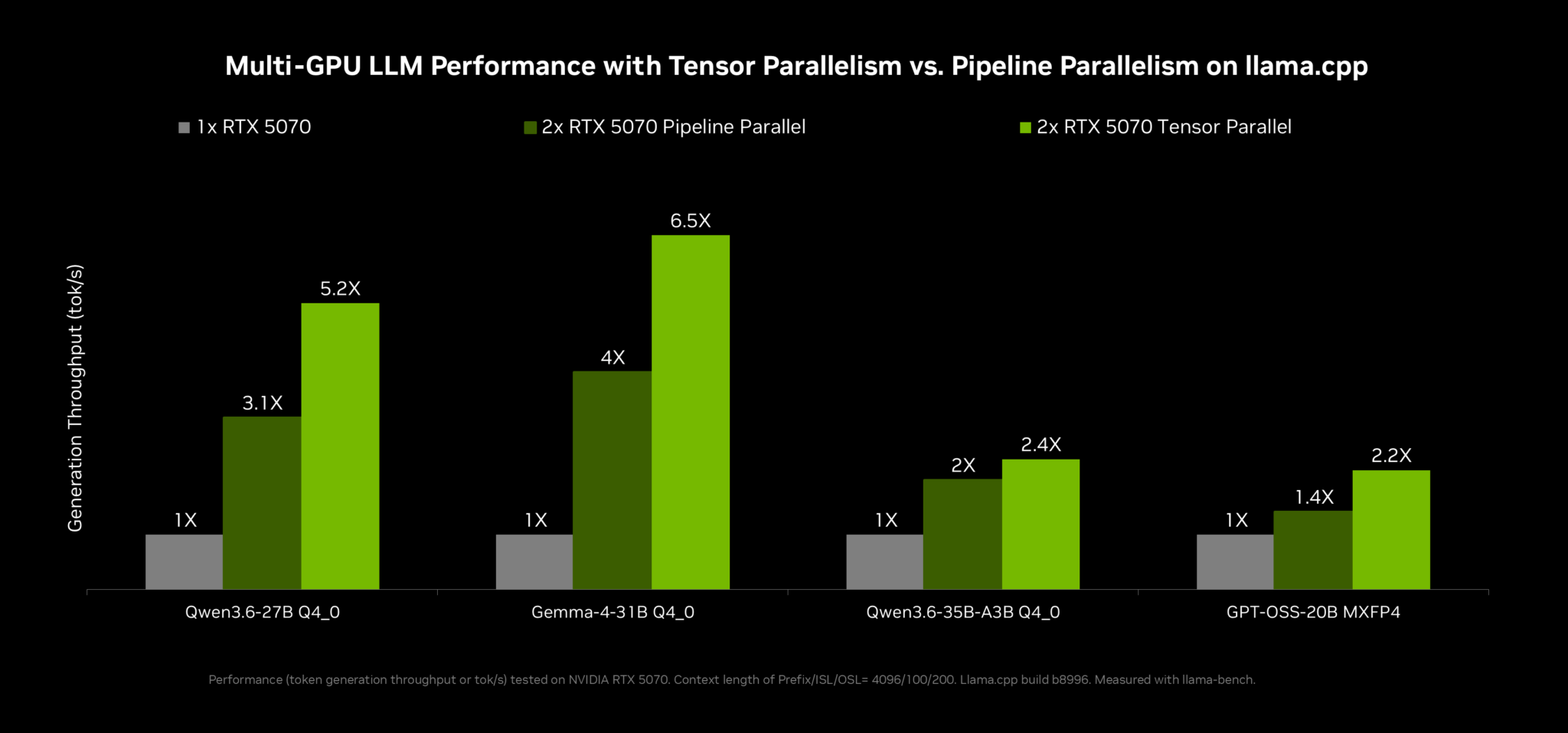
vLLM은 DGX Spark 환경에서 NVFP4 체크포인트 최적화와 커널 개선을 통해 기존 대비 2.6배의 추론 성능을 기록했다.
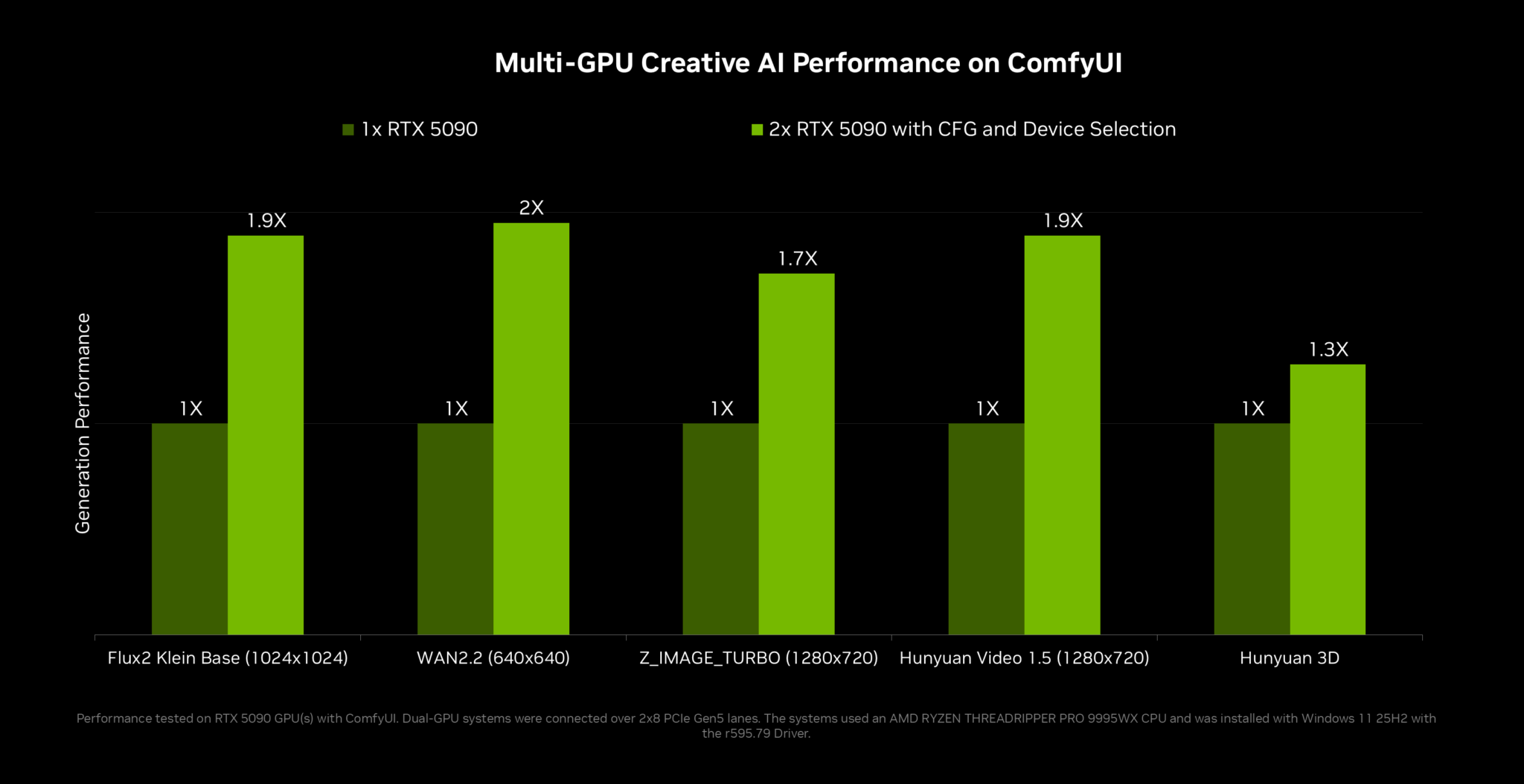
Adobe Premiere와 Photoshop은 RTX Spark의 통합 메모리와 Blackwell GPU를 활용하도록 재설계되어 AI 기반 편집 및 효과 처리 성능이 최대 2배 개선된다.
RTX Video Frame Generation은 ComfyUI 노드 및 Python 휠 형태로 제공되어 AI 모델이 생성한 저프레임 영상의 재생 속도를 실시간으로 보간한다.
실무 Takeaway
- RTX Spark 플랫폼은 1 페타플롭급 연산과 128GB 메모리를 제공하여 로컬 환경에서 고성능 AI 에이전트 구동을 지원한다.
- llama.cpp와 vLLM의 최신 최적화(MTP, 텐서 병렬 처리)를 적용하면 로컬 LLM 추론 처리량을 최대 2배 이상 향상할 수 있다.
- OpenShell 런타임과 Windows 보안 프리미티브를 활용하면 로컬 에이전트의 데이터 보안과 사용자 제어권을 강화할 수 있다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 01.수집 2026. 06. 01.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.