핵심 요약
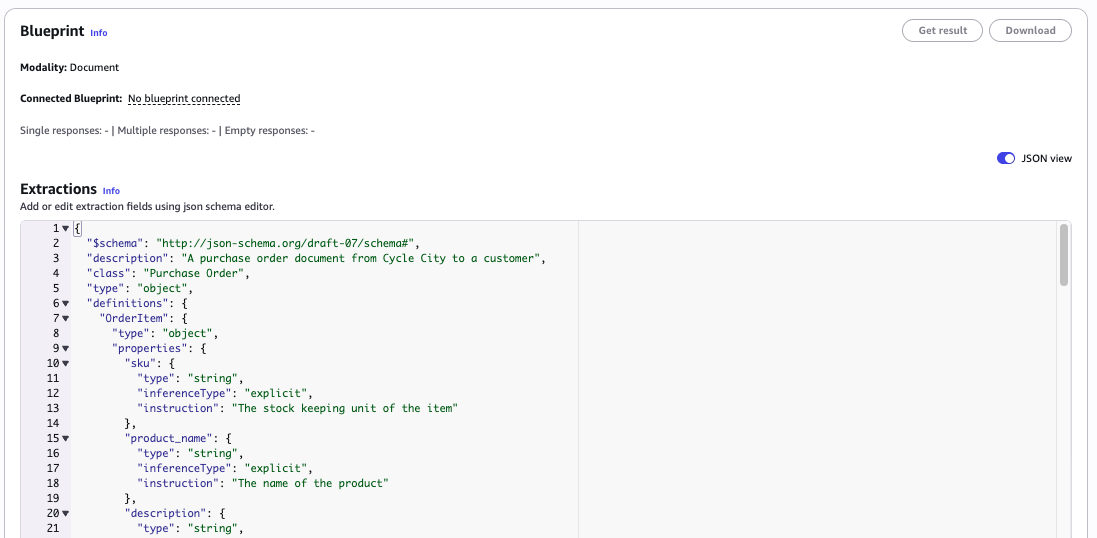
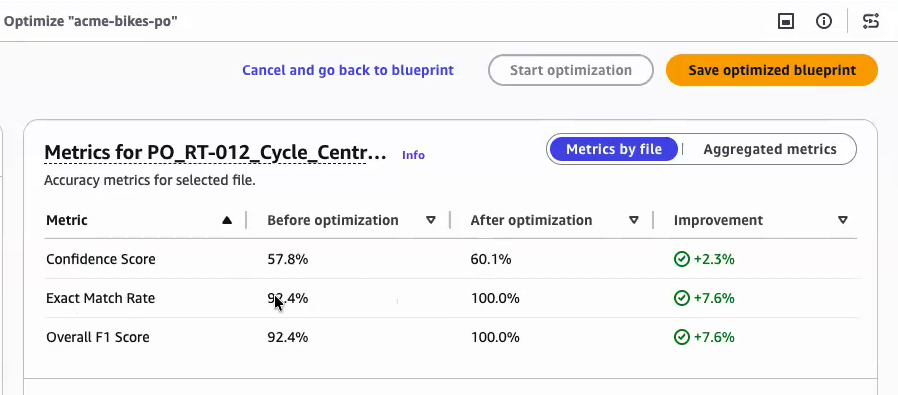
Amazon Bedrock Data Automation(BDA)은 비정형 문서에서 데이터를 추출하는 지능형 문서 처리(IDP) 파이프라인을 구축하는 서비스이다. 기존에는 문서 형식 변화에 대응하기 위해 수동으로 추출 명령어를 반복 수정해야 했으나, 블루프린트 명령어 최적화 기능은 예시 문서와 정답지(ground truth)를 기반으로 명령어를 자동 개선한다. 사용자는 3~10개의 예시를 제공하여 몇 분 만에 정확도를 높일 수 있으며, 별도의 모델 파인튜닝 과정은 필요하지 않다. 이 기능은 정확도 지표인 F1 점수와 일치율(Exact Match Rate)을 제공하여 최적화 결과를 정량적으로 검증할 수 있게 한다.
배경
AWS 계정, Amazon Bedrock Data Automation이 활성화된 리전 접근 권한, IAM 권한 (Bedrock 및 S3), 3~10개의 샘플 문서 및 정답지 JSON 파일
대상 독자
프로덕션 환경에서 지능형 문서 처리(IDP) 파이프라인을 구축하는 개발자 및 데이터 엔지니어
의미 / 영향
이 기능은 문서 처리 자동화의 진입 장벽을 낮추어 기업이 더 빠르고 정확하게 비정형 데이터를 구조화할 수 있게 한다. 특히 RAG 및 에이전트 워크플로의 기반이 되는 데이터 품질을 향상시켜 AI 시스템의 신뢰성을 높이는 데 기여한다.
섹션별 상세
실무 Takeaway
- 반복적인 문서 추출 튜닝이 필요한 경우, 3~10개의 대표 문서와 정답지를 준비하여 BDA의 자동 최적화 기능을 활용하면 개발 시간을 대폭 절감할 수 있다.
- 최적화 결과는 F1 점수와 일치율로 검증 가능하며, 성능이 부족한 경우 특정 문서 유형을 추가하여 재최적화를 수행하는 반복 프로세스를 권장한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.